- Published on
Quando a Observabilidade encontra a IA
- Authors

- Name
- Leandro Simões
Capítulo 1 — Transformando logs em vetores: o pipeline de embedding
Por que embedding?
Na demo que montei para a Tech Hub Conf, a aplicação já estava instrumentada: traces no Tempo, logs no Loki, métricas no Prometheus, tudo visível no Grafana. Isso resolve perguntas do tipo, "onde está o problema?", mas não resolve outra que aparece com frequência em incidentes: "o que aconteceu de parecido com isso antes?" ou "existiu algum erro de conexão com o banco?"
Buscar por palavra-chave no Loki funciona quando você sabe exatamente o que procurar. Quando a pergunta é conceitual, a busca literal falha. A saída foi indexar os logs como vetores semânticos e guardá-los no PostgreSQL com pgvector, reutilizando o mesmo banco da aplicação.
O caminho do log até o vetor
A API emite logs estruturados via interceptor HTTP. Cada requisição gera uma linha no formato:
http_request method=POST route=/transactions status=201 duration_ms=42
O OpenTelemetry Collector encaminha esses logs ao Loki. O Grafana Alloy coleta logs dos containers Docker e também os envia ao Loki. A partir daí entra o serviço log-embedder, um worker que roda em loop independente da API.
Polling incremental no Loki
O embedder não reprocessa tudo a cada ciclo. Ele mantém um cursor em nanosegundos na tabela log_embedder_cursor. A cada poll (30 segundos por padrão), consulta o Loki com query_range a partir desse cursor:
const params = new URLSearchParams({
query: '{source="alloy-otel"}',
start: cursorNs.toString(),
end: endNs.toString(),
limit: '5000',
direction: 'forward',
});
Na primeira execução, com cursor zerado, ele faz um lookback (24 horas por padrão) para não perder histórico. Depois disso, só processa linhas novas. Quando termina um batch, avança o cursor para maxNs + 1, garantindo que a mesma linha não seja reprocessada.
Enriquecimento antes de embedar
Log bruto do Loki raramente é ideal para embedding. O parser extrai metadados úteis de cada linha:
- service — nome do serviço/container
- level — INFO, ERROR, etc.
- trace_id — para correlacionar com traces no Grafana
- route, http_method, status_code — parseados da linha
http_request
Antes de chamar a OpenAI, monto um texto enriquecido com contexto — ainda é texto legível, não o vetor:
// Exemplo de saída do formatEmbedText:
[level=ERROR] [service=app] [POST /transactions] [status=500] [trace_id=abc123...] http_request method=POST route=/transactions status=500 duration_ms=1203
Enriquecimento e embedding são etapas distintas: o primeiro produz a string com metadados (campo content); o segundo transforma essa string no array numérico da coluna embedding. Esse prefixo faz diferença na qualidade da busca semântica. O modelo passa a "saber" que aquela linha é um erro 500 num POST específico, não apenas uma string genérica.
Embedding e persistência
Usei o modelo text-embedding-3-small da OpenAI via LangChain.
No PostgreSQL, a tabela log_embeddings guarda tanto o texto enriquecido quanto o vetor:
CREATE TABLE log_embeddings (
id UUID PRIMARY KEY,
loki_ts TIMESTAMPTZ NOT NULL,
content TEXT NOT NULL,
embedding vector(768),
trace_id TEXT,
service TEXT,
level TEXT,
route TEXT,
http_method TEXT,
status_code INT,
line_hash TEXT UNIQUE
);
CREATE INDEX log_embeddings_embedding_idx
ON log_embeddings
USING hnsw (embedding vector_cosine_ops);
O índice HNSW (Hierarchical Navigable Small World) acelera buscas por similaridade de cosseno. Sem ele, cada consulta faria scan completo, ok no meu exemplo porém seria inviável com milhares de linhas.
Para evitar duplicatas quando o Loki reentrega a mesma linha, calculo um hash SHA-256 combinando labels, timestamp e conteúdo. O insert usa ON CONFLICT (line_hash) DO UPDATE, atualizando campos que podem ter sido enriquecidos depois (route, status_code).
O que isso habilita
Com os logs embedados, duas coisas ficam possíveis:
- Busca semântica —
GET /logs/search?q=problema de timeout no bancoretorna linhas parecidas, mesmo sem a palavra "timeout" no log original. - Base para Q&A — no capítulo seguinte, esses vetores alimentam o RAG que responde perguntas analíticas.
A escolha de manter tudo no PostgreSQL (em vez de um vector DB dedicado) foi por pura conveniência e não uma escolha fundamentada.
Capítulo 2 — Perguntas em linguagem natural: LLM Planner, SQL e RAG
O endpoint
Com os embeddings prontos, expus um endpoint POST /logs/ask que recebe uma pergunta em português e devolve uma resposta baseada nos logs:
{ "question": "Quantas falhas no endpoint /users na última hora?" }
A resposta inclui o texto gerado, o plano de execução (para debug/transparência), métricas agregadas quando aplicável, e as evidências (logs) usadas para compor a resposta.
Aqui não podia simplesmente chamar uma LLM, ela provavelmente iria alucinar, inventar dados, se perder no meio do caminho e etc. Contexto é a palavra chave quando falamos de LLMs, por isso precisei trabalhar bem os dados antes de enviar para a LLM.
O LLM Planner: três modos de resposta
Após receber a pergunta do usuário, envio essa pergunta para o LLM Planner, que decide como respondê-la usando três formas diferentes:
- Aggregate — perguntas cuja resposta pode ser apenas um número. Exemplo: "Quantas falhas no endpoint X?"
- RAG — perguntas mais abertas, onde a resposta depende de encontrar logs semanticamente relevantes. Exemplo: "Houve problema de conexão com o banco de dados?"
- Híbrido — quando se espera números e detalhes. Exemplo: "Quantas chamadas no endpoint X na última hora?"
O fluxo de resposta ficou assim:
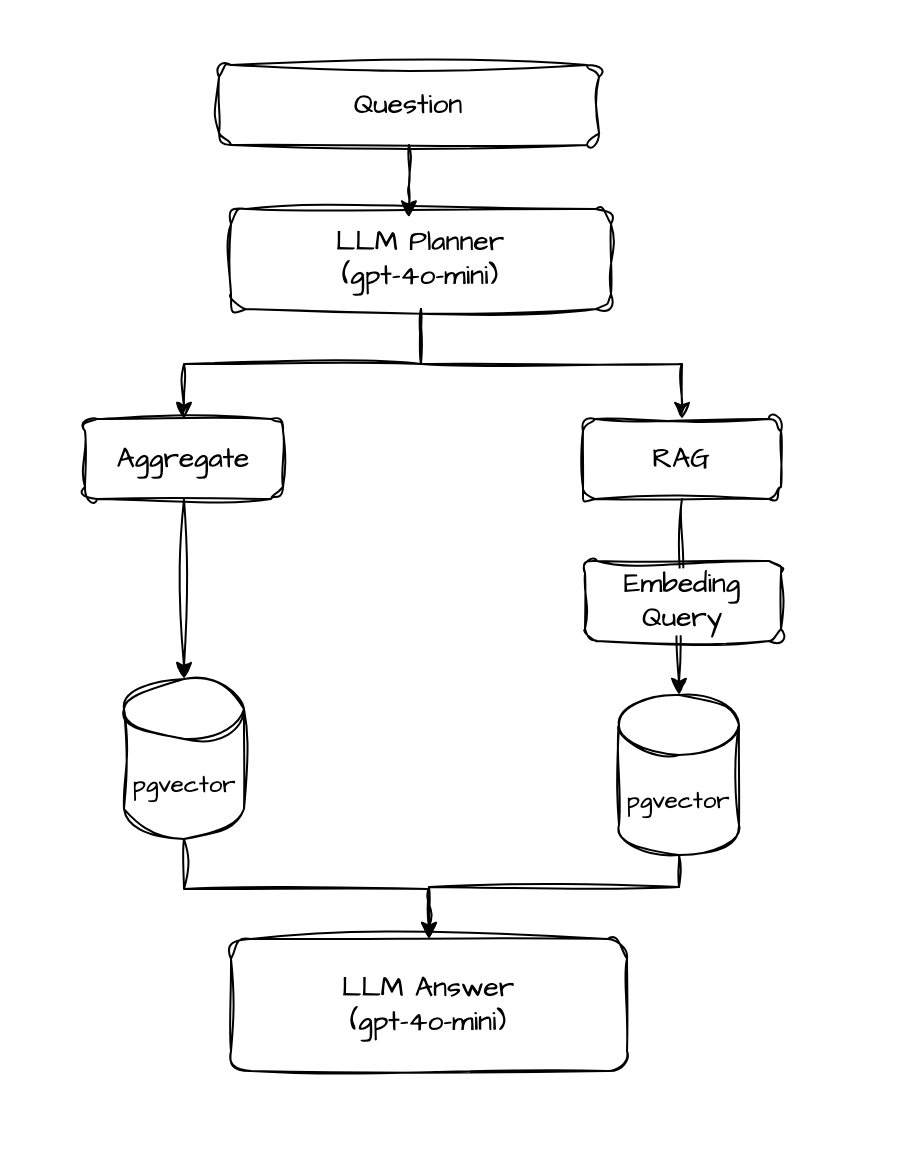
O planner usa gpt-4o-mini com temperatura zero e retorna um JSON estruturado:
{
"mode": "hybrid",
"timeWindow": { "amount": 1, "unit": "hour" },
"filters": { "route": "/users", "httpMethod": "GET" },
"aggregation": "count_http_requests",
"listLogs": true,
"limit": 30,
"ragQuery": "quantas chamadas GET /users na última hora"
}
Campos importantes do plano:
| Campo | Função |
|---|---|
timeWindow | Janela temporal ("última hora", "hoje", "24 horas") |
filters | Restrições: level, route, httpMethod |
aggregation | Tipo de contagem SQL a executar |
listLogs | Se deve trazer logs individuais como evidência |
ragQuery | Texto reformulado para busca semântica |
Se o LLM falhar (timeout, JSON inválido), um fallback heurístico assume: regex detecta "quantas", "quais", "houve", infere rota e método HTTP da pergunta, e monta um plano razoável sem depender do modelo. Bom, se até a Antropic pode usar regex para identificar palavrões então eu também posso!
Aggregate: SQL resolve, LLM só narra
No modo aggregate, a resposta numérica vem de SQL direto sobre log_embeddings.
Três agregações cobrem os casos principais:
count_failures— conta logs comlevel = ERRORoustatus_code >= 500, respeitando filtros de rota/método.top_route_by_count— ranking de rotas com mais falhas no período.count_http_requests— conta chamadas a um endpoint específico (ex.: POST/transactions).
Para "Quantas falhas no endpoint /users?", o planner gera mode: aggregate, aggregation: count_failures, filters: { route: "/users", level: "ERROR" }. O repositório executa:
SELECT count(*) FROM log_embeddings
WHERE loki_ts >= $1 AND loki_ts < $2
AND route = '/users'
AND (level = 'ERROR' OR status_code >= 500)
RAG: busca semântica com filtros
No modo RAG, a pergunta é embedada com o mesmo modelo usado na indexação, e o PostgreSQL faz busca por similaridade de cosseno:
SELECT content, 1 - (embedding <=> $1::vector) AS score
FROM log_embeddings
WHERE loki_ts >= $2 AND loki_ts < $3
ORDER BY embedding <=> $1::vector
LIMIT $4
Os filtros do planner (level, route, httpMethod) são aplicados antes da ordenação por score. Isso evita que um log semanticamente parecido, mas de outra rota, apareça na resposta.
Logs com score abaixo de 0.65 são descartados, melhor dizer "não encontrei" do que mostrar evidência fraca ou inventar.
Para "Houve problema de conexão com o banco?", o planner gera mode: rag sem agregação. A busca semântica encontra linhas com mensagens de timeout, connection refused ou similares, mesmo que a pergunta não use essas palavras exatas.
Híbrido: número + evidência
O modo híbrido combina aggregate e RAG. É o mais comum na prática porque perguntas reais raramente pedem só um número ou só contexto.
Para "Quantas chamadas GET /users na última hora?":
- O planner gera
mode: hybrid,aggregation: count_http_requests,listLogs: true. - SQL conta as requisições GET
/usersno período. - SQL lista os logs individuais desse endpoint (priorizando match exato por conteúdo, caindo para RAG se necessário).
- O LLM de síntese recebe
{ count: 47, evidence: [...] }e responde: "Foram 47 chamadas GET /users na última hora. Exemplos: [...]".
Para "Houve transação criada hoje?", o planner infere POST /transactions, conta as chamadas, e lista os logs com status 201, confirmando a operação com evidência concreta.
Síntense: LLM dá a resposta, não inventa dados.
O último passo é o Answer Service. Ele recebe a pergunta original, as métricas SQL e até 20 evidências, e gera a resposta final em português.
As regras do system prompt são deliberadamente restritivas:
- Usar apenas os números presentes em
metrics, nunca inventar contagens. - Para perguntas sim/não, confirmar ou negar com base nas evidências.
- Logs INFO com status 2xx indicam sucesso (POST 201 = transação criada).
- Quando a pergunta pede "quais" ou "houve", listar os logs — não resumir com um número solto.
Se o LLM retornar resposta vazia ou contraditória ("não houve" quando há evidências), um fallback determinístico formata a resposta diretamente dos dados, sem modelo.
Por que separar planner, SQL e síntese?
Lembre-se, contexto é a palavra chave para extrair o máximo das LLMs, seria fácil e até tentador jogar todos os logs numa LLM e deixa-la responder qualquer tipo de pergunta, porém sabemos que isso pode não funcionar em muitos casos. A LLM vai alucinar, estourar a janela de contexto e começa a dar respostas sem sentido.
Além disso algumas perguntas, ou partes da pergunta, podem ser respondidads com SQL, uma vez que já extraímos metadados estruturados dos logs (route, status_code, level) no enriquecimento do Capítulo 1.
Observabilidade responde "o que aconteceu?". Com embedding + RAG + planner, conseguimos responder perguntas mais humanas, em linguagem natural, com números e logs como prova.